I talked yesterday about the vision of building exoskeletons for online communities. I’ll share here a progress update on the work we’ve been doing towards building an epistemic exoskeleton over the past two days with @xiq.
Work philosophy.
We want to find high-leverage opportunities where one hour of work translates into as much gain in community epistemics as possible. To achieve this, we are betting on the future progress of AI capabilities, especially agentic capabilities.
Many tools built on top of the Community Archive Twitter data have been developed using semantic embeddings (see Magic Search, Birdseye or Nomic’s embedding atlas). Even though there are many interesting directions for improving our current embedding tech stack (e.g., adding temporally aware embeddings or prompt-guided embeddings), the returns are likely to saturate in the coming years. It is hard to envision how better embeddings would double the effectiveness of today’s applications or open up new designs that are unthinkable with today’s embedding technology (if you disagree, I would love to hear your thoughts!). In short, it feels unrealistic to expect embeddings in five years to deliver twice as much value as they do today.
In contrast, it is very likely that agentic capabilities will continue to advance. Our current best single source of evidence is the METR study which shows that the time horizon of tasks AI agents can complete doubles every seven months. Having an AI agent that can reliably complete research tasks that normally take humans 26 minutes (GPT-5’s current time horizon for an 80% success rate) or six hours (predicted performance in two years if the trend continues) can be a game changer for the types of applications we can build.
This is guiding the way we think about our work. The output at long/medium term is something like journalist AI agents documenting community discourse. This has the potential to increase up dramatically the availability of high-quality sense-making and epistemic community services.
To that end, in the short-term, we are working to deliver two kinds of outputs:
- Manual research reports mapping the evolution of online discourse over time, which are valuable to the community.
- Technical primitives (e.g., embedding search and clustering, X thread manipulation tools, heuristic metrics to filter data, etc.) that support the research process.
The manual analyses can be thought of as high-quality few-shot examples that will guide the future AI journalist agent in demonstrating the kind of output we are interested in producing, while the technical primitives will serve as its toolbox.
Early progress report.
Data pipeline.
- Loaded 300 million tweets from the community archive along with their embeddings from Qwen3-4b. Importantly, the text of the embeddings is stripped of usernames like “@exgenesis.” This tends to create embeddings that cluster around usernames instead of semantics.
- Reduced the dimension from 1024 to 5 using UMAP.
- Ran KMeans to find 550 clusters (chosen to be roughly the square root of 300,000, the dataset size).
- For each cluster, picked consecutive chunks of tweets that span the entire time range of the cluster (e.g., a chunk of 10 consecutive tweets at the start, 10 in the middle, and 10 at the end). Asked a language model (here, OpenAI’s OSS-20b) to give a name to the cluster and rate its quality. We used a rubric made up of three scores, as defined in the prompt:
- discourse coherence (0-10): Not just thematic similarity but actual conversational threading - are people responding to/building on each other’s ideas? Referencing the same specific events, papers, people? You want to distinguish “everyone talking about AI” from “everyone discussing that specific Yudkowsky post from Tuesday.”
- generative density (0-10): This is your “new cultural production” metric. Are people synthesizing? Coining terms? Creating frameworks? You can spot this through novel metaphors, emergent terminology, conceptual bridges between previously unconnected ideas. A cluster about “animals” scores low, but “applying predator-prey dynamics to social media algorithms” might score high.
- temporal coherence (0-10): Does the cluster represent an actual unfolding discourse with a beginning, middle, and development? Or is it just random samples of similar content across time? Look for cascading responses, evolution of arguments, and people changing positions.
- We then looked at the cluster with the highest average score among the three dimensions. We also examined the evolution of tweets in the cluster over time to check for interesting trends.
- Finally, we selected interesting clusters and used Claude to analyze all the tweets in the cluster (often around 1,000 tweets) and extract interesting strands of discourse that unfold over the years.
Here are a few plots of the data.
 2D UMAP plot (for visualization only) of a subset of the tweets. Colors correspond to the clusters; the crosses indicate the clusters’ centroids.
2D UMAP plot (for visualization only) of a subset of the tweets. Colors correspond to the clusters; the crosses indicate the clusters’ centroids.
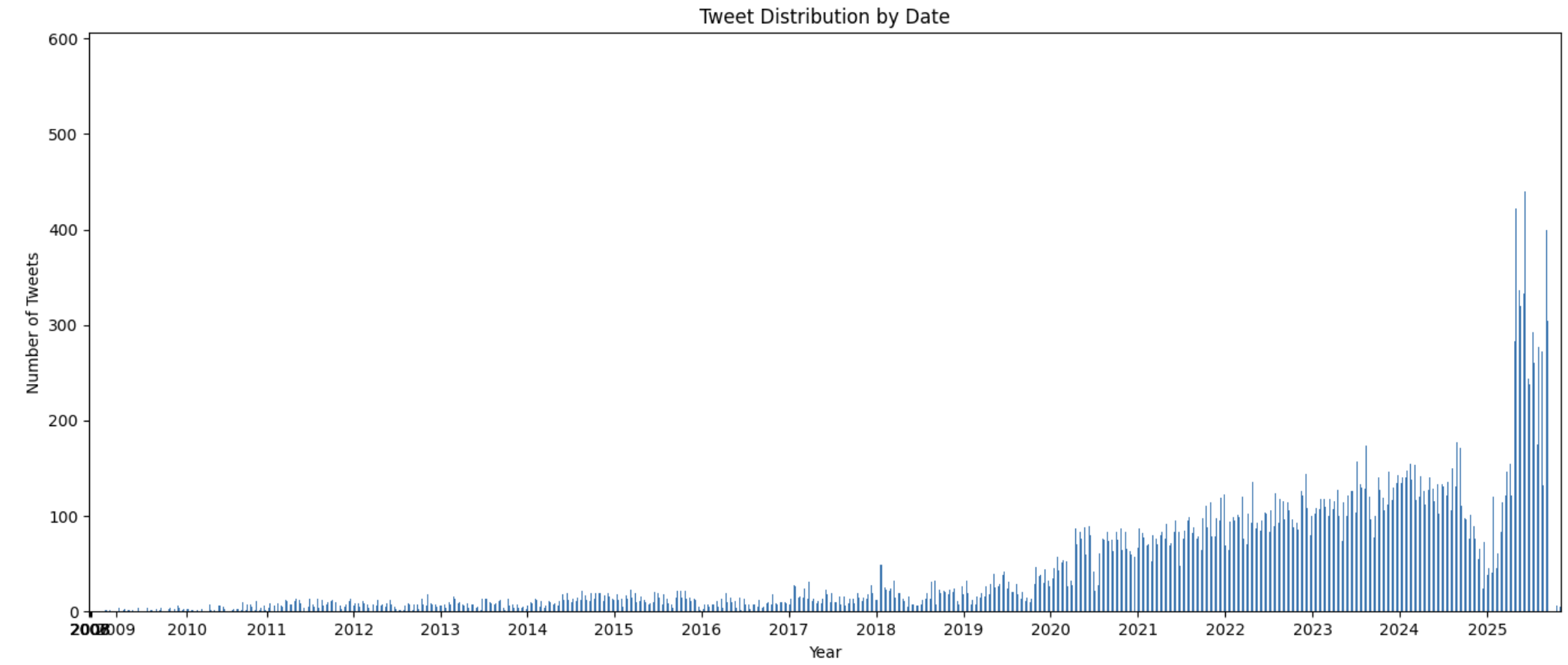 Volume of tweets over time. Most tweets are recent.
Volume of tweets over time. Most tweets are recent.
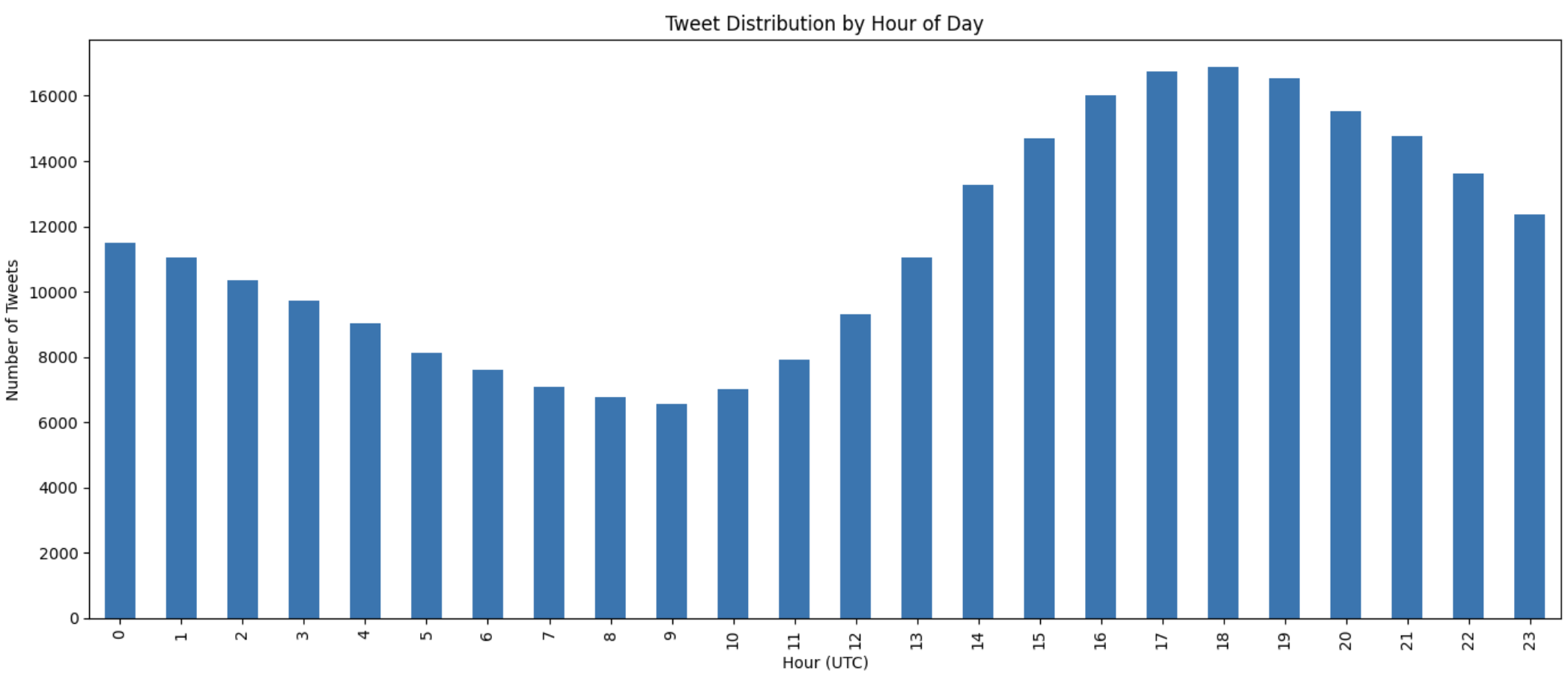 Volume of tweets accross UTC time. The East Coast timezone dominates the trend, as 9am UTC is 4am EST.
Volume of tweets accross UTC time. The East Coast timezone dominates the trend, as 9am UTC is 4am EST.
Early results.
Here are a few findings from this data pipeline from one day of work. They are signs of life the techniques we used can surface non-trivial phenomena that might be good starting points for manual analysis.
The Sangha is the new Buddha
In the cluster called “Digital Sangha Narrative,” we have a series of tweets spanning several years:
-
“The next Buddha may take the form of a community – a community practicing understanding and loving kindness…” – Thich Nhat Hanh
- 2009/06/27 @technoshaman
-
.@szpak Mark, do you have some reference to Chogyam #Trungpa’s saying that #Maitreya, the Buddha of the future, will not be an individual but #society?
- [2011-02-27] @technoshaman
-
RT @dthorson: The next Buddha is sangha. The next sangha is the network. The next Buddha is the network.
- [2018-02-02] @tasshinfogleman
-
The next Buddha will be a manga.
- [2023-05-17] @the_wilderless
-
Divinely protected
God’s hand selected
Hivemind infectedThe next Buddha is a sangha.
The incoming prophet is a collective.
- [2025-06-20] @mudscryer
-
The next Buddha is a sangha (TPOT).
- [2025-09-10] @nosilverv
It starts with a quote from Thich Nhat Hanh in the early days of Twitter in 2009, with a few variations over the years. By 2025, now TPOT (This Place of Twitter) has become a thing, the sangha is TPOT.
Crypto and Bitcoin Trends
We have two clusters related to crypto: one called Tokenization & Crypto Evolution and the other Bitcoin Evolution Narrative. The number of tweets in this cluster over time matches the four-year cycles of Bitcoin, with clear spikes in activity in late 2013, 2017, 2021, and 2025. We are unsure about how significant this is, it was consistent enough to be worth reporting.
Here is a plot showing the activity of the two crypto cluster (blue and orange curves) as well as the “Digital Sangha Narrative” cluster (in green) as a control. Below the plot is the Bitcoin price curve with a logarithmic y-axis for comparison.
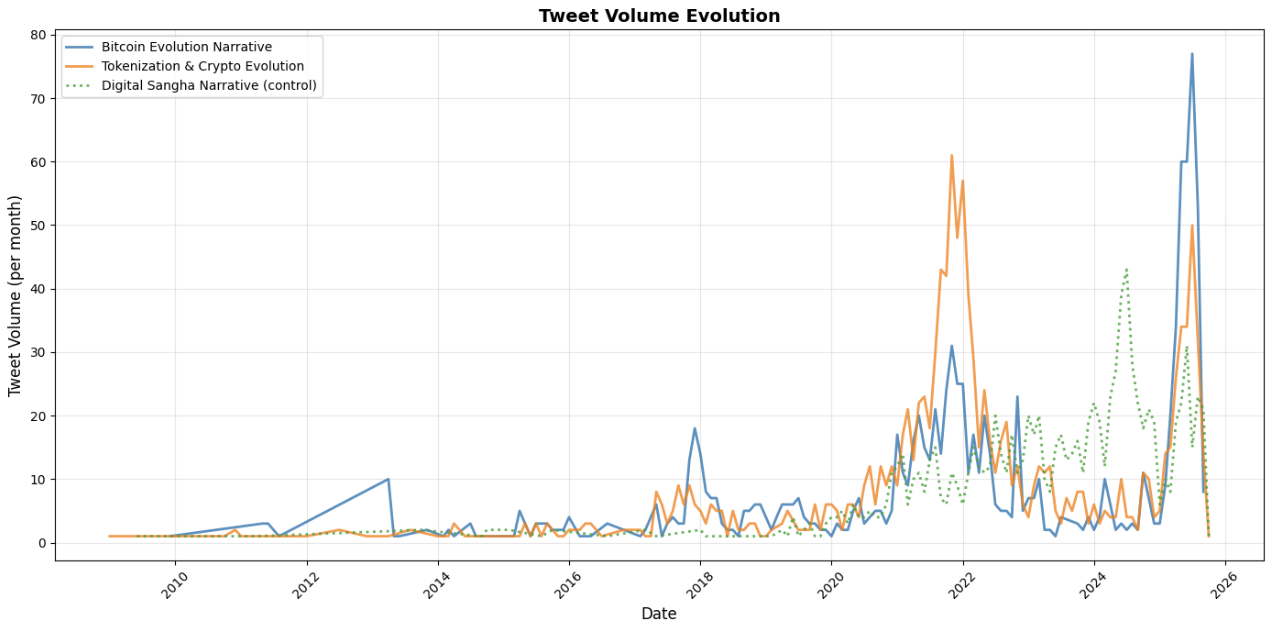
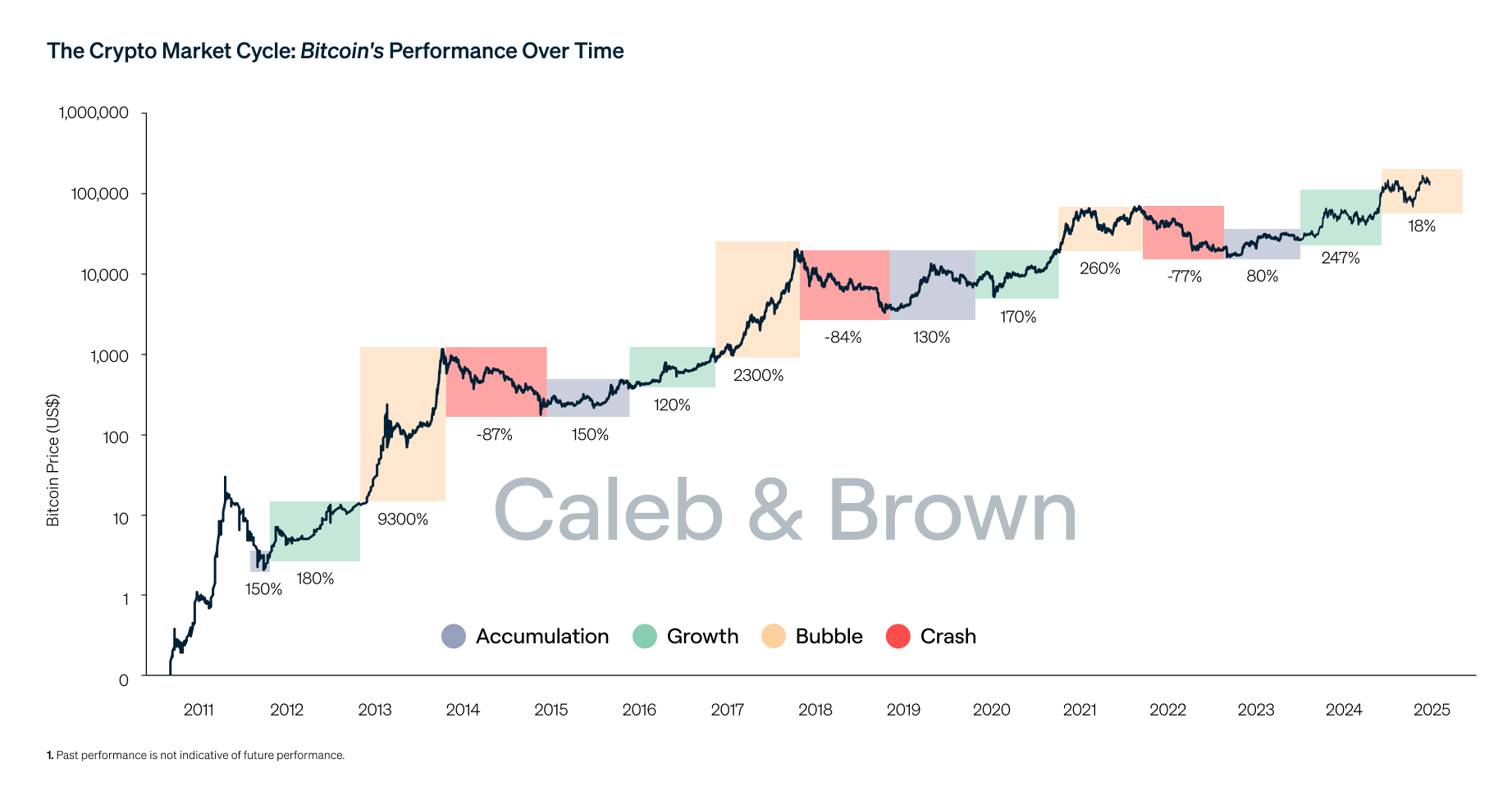
Departing thoughts
If you are interested in exploring the content of the clusters yourself, you can download a zip file with the 550 clusters here. AI has the potential to bring chaotic dynamics to the information sphere, we are excited to find ways to balanced this with stronger online communities!
Want to hear when I post something new?